昨日、こちら(ジョージア大学)のDishman教授からe-mailをもらった。
I have placed a copy of a data list indicating each repeated measure as a separate variable.
とのこと。その2日前に、彼の研究室で今後の仕事のことにつ いてミーティングをしたときに、「それまで私が処理していた 実験データのファイルをこちらの研究室に残すにあたって、彼 が使っているSPSSのプログラムで処理しやすいように、ファイ ル形式を変換する」ことになった。その際、彼が望んでいるデー タの記述形式について話を聞いたのだが、私が理解に苦しんだ ので、彼がそのデータ記述形式の見本を私の(郵便)BOXに入 れ、それを参考にして私がデータ記述形式の変換をするという 手はずになったのだった。
この実験の被験者は現在の所26名![]() で、各被験者は7種類の試
行を行っている。それぞれの試行についてほぼ同等の測定を行っ
ているため、私は以下のような変数からなるデータファイルを
作っていた。
で、各被験者は7種類の試
行を行っている。それぞれの試行についてほぼ同等の測定を行っ
ているため、私は以下のような変数からなるデータファイルを
作っていた。
被験者(s)/作業試行(t)/変数1/変数2/変数3/…
すなわち、一つの作業試行毎に一行のデータが生成されるわけ で、このファイルには合計26人×7試行=182行のデータがある。 私はこのようなデータ整列形式を「美しい」と思うし、「便利」 と思いこんでいたので、このようなファイルしか作らなかった のだが、どうやらDishman教授にはこの「美しさ」が理解でき ないらしい。彼が望むデータ記述形式は、「繰り返されるデー タは各々別個の変数として記述する」というものであり、以下 のように一人の被験者のデータは全て一行に含まれてしまうの である。
被験者/試行1(変数1)/試行1(変数2)/試行2(変数1)/試行2(変数2)/…
私には、このように横にだらだらと節操なく並べていくのが愉
快ではないのだが、これだと作業試行の行数分だけ同じ被験者
変数を繰り返し記述する必要がない。だいたい、私の記述形式
では、たとえば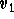 のように被験者に固有の
データも全ての行に繰り返して記載しなければならない。ディ
スクスペースを節約できるという意味では、彼の記述の方が優
れているし美しい。彼からのe-mailの後半に記されていた以下
の指示は明瞭である。
のように被験者に固有の
データも全ての行に繰り返して記載しなければならない。ディ
スクスペースを節約できるという意味では、彼の記述の方が優
れているし美しい。彼からのe-mailの後半に記されていた以下
の指示は明瞭である。
Rows are subjects, columns are variables.
つまり、作業試行毎に「ほとんど同じ測定」をするといっても、 厳密には全く同じことをしているわけではない(作業が違うの だから全く同じになるはずがない)。だが、「被験者」につい ては、確かに同じプロトコルの繰り返しであるから、個別の行 に並列記述することに無理無駄がない。
う~ん、でも何かおかしいなぁ。じゃぁ、なんで私はそういう やり方をしていたのだろう。理由ははっきりしている。つまり、 私がやったように作業試行毎に個別の行に記述しないと、試行 間の分散分析ができないからなのだ。私が使っているSASの入 門書には以下のようにはっきりと書いてある。
分散分析とは分類変数(classification variables)を独立変数 とした線形モデルを作り、分散を分解することによってそれぞ れの独立変数が従属変数に及ぼす効果を調べるための手法の総 称である。
つまり、「独立変数」としての分類変数を明示しなければ処理 できないはずなのである。いったい、Dishmanはそのような解 析をやらないっていうわけなのだろうか?そんなはずはありえ ない。だいたい彼の統計処理技術は、アメリカのスポーツ科学 界でだれもが一目置くほどのもので、それが彼の数々の業績を 支えているわけだ。私がやるような平凡な統計解析を彼が考慮 しないはずがない。じゃぁ、彼の使っているSPSSでは異なる概 念でデータを解析しているのだろうか。そこで私は彼に尋ねて みた。
The question is how you describe the SPSS command when you want to investigate the ANOVA between variables described in same row.
すぐに答えが返ってきた。「明日朝10:30頃に研究室に来てく
れたら教える」とのこと。しょうがないから、また彼に会いに
出かけた![]() 。といっても、彼も私の質問の意味が分
からなかったらしく、「論より証拠」と実際に彼のコンピュー
タでSPSSを実演してもらった。何のことはない、彼のマシンの
Windows95から立ち上がるその統計パッケージでは、分析した
いデータ変数をクリックして処理内容を指示するだけで、即座
に結果が出力されるようになっていたのだ。「コマンド」なん
ていう概念がもはや消失していたのだった。
。といっても、彼も私の質問の意味が分
からなかったらしく、「論より証拠」と実際に彼のコンピュー
タでSPSSを実演してもらった。何のことはない、彼のマシンの
Windows95から立ち上がるその統計パッケージでは、分析した
いデータ変数をクリックして処理内容を指示するだけで、即座
に結果が出力されるようになっていたのだ。「コマンド」なん
ていう概念がもはや消失していたのだった。
結局のところ、私と彼とのデータファイルの記述様式の違いは、 使っている統計環境の差に起因するものだった。なにしろ、彼 の環境は「魅力的」である。一度その専用データファイルを作 ると、その統合環境の中で自由に「表計算処理」ができるばか りか、結果のグラフ作成までやってくれる。図表のプリンタ出 力も容易で、それがそのまま論文用の図表になるようだ。しか し、私はその「魅力的環境」に引きつけられるわけにはいかな い。なにしろ、それは私が築きあげてきた研究環境とはあまり にも違い、そこに乗り移るにはこれまでの時間的な投資を捨て るだけでなく、新たに多大な投資を必要とするからだ。考えて みれば、研究者が100人いればデータの取り扱いにも100様のや り方があるはずで、全く同じコンピュータ環境である方が希だ ろう。なにしろ、研究対象も周囲の環境も作成文書の様式も、 なにからなにまで一緒ということはありえないからだ。
コンピュータとかインターネットというと、いつでも「標準的」 で「規範的」な環境を与えてくれて、誰がやっても同じになる ように感じがちであるが、実際には「誰がやるか」によって微 妙に(あるいは非常に)違うのだ。少なくとも科学研究につい てはそれは自明である。なぜなら、誰がやっても全く同じよう にしかならないのであれば、その産物である「研究論文」のオー サーシップには意味がなくなるからである。だから、少なくと もそれが科学研究である限り、完璧な「同一性」あるいは「互 換性」を求めるのは無理があるのだ。…。
と、まあ、彼と二時間ばかりしゃべりながら、そんなことが頭 をよぎったのであった。だから、私のデータファイルを彼の記 述様式に変換するのもやむを得ないのである。でも、なんだっ てその「変換」を私がやってやらなければならないのだろうか。 理由は簡単だ。それは、彼が教授で私が単なる訪問研究者だか らなのではない。私がやる方が容易だからである。